Joined LIOPS
Started as a 3D AI Engineer at LIOPS, working on stereo depth estimation while continuing broader interests in 3D vision and multimodal AI.
3D AI Engineer at LIOPS · Researcher in 3D Vision and Multimodal AI
I am a 3D AI Engineer at LIOPS, where I work on stereo depth estimation for 3D AI and vision systems. My research background comes from the Vision & Learning Lab at UNIST, where I worked under the supervision of Prof. Seungryul Baek and Prof. Binod Bhattarai. My research focuses on multimodal learning and vision-language models, with an emphasis on structured and grounded reasoning in complex visual environments, particularly involving articulated hands and human-object interactions.
My recent work develops large-scale benchmarks and real-time Transformer architectures that integrate explicit 3D geometric supervision into multimodal models, improving fine-grained spatial reasoning reliability and cross-task generalization.
I am currently interested in advancing multimodal foundation models toward more reliable and interpretable reasoning, and in translating 3D perception research into practical depth-estimation systems, with long-term directions in grounded world models and embodied multimodal systems that integrate perception, language, and action.
I am always open to collaborations and discussions. If you are interested in my research or have any inquiries, feel free to reach out to me at khalequzzamansayem@gmail.com.

Started as a 3D AI Engineer at LIOPS, working on stereo depth estimation while continuing broader interests in 3D vision and multimodal AI.
Our HandVQA paper is now available on arXiv.
Our paper on diagnosing and improving fine-grained spatial reasoning about hands in vision-language models has been accepted to CVPR 2026.
Started my role as a Researcher at UNIST Vision & Learning Lab, continuing work on grounded multimodal reasoning.
Successfully defended my master's thesis and graduated from UNIST.
Our paper on real-time two-hand and object understanding was accepted to AAAI 2025.
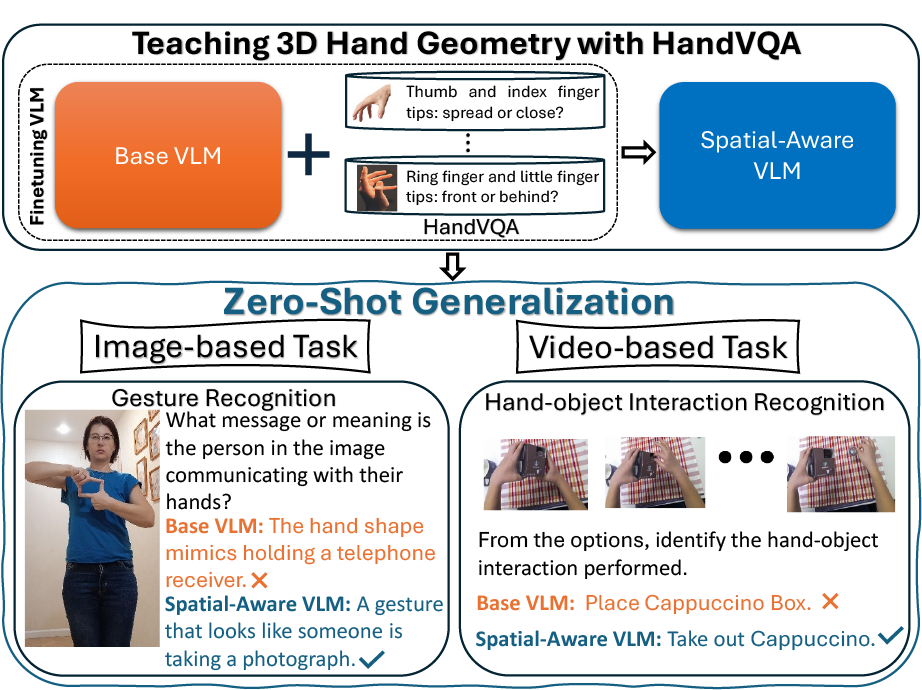
In this paper, we introduce HandVQA, a large-scale benchmark grounded in 3D hand geometry to systematically evaluate fine-grained spatial reasoning in Vision-Language Models (VLMs). The dataset contains 1.6M+ geometry-derived VQA pairs spanning joint angles, distances, and relative spatial relations (X/Y/Z). We demonstrate that explicit 3D supervision significantly improves spatial reasoning reliability and generalizes to gesture recognition and hand-object interaction tasks.
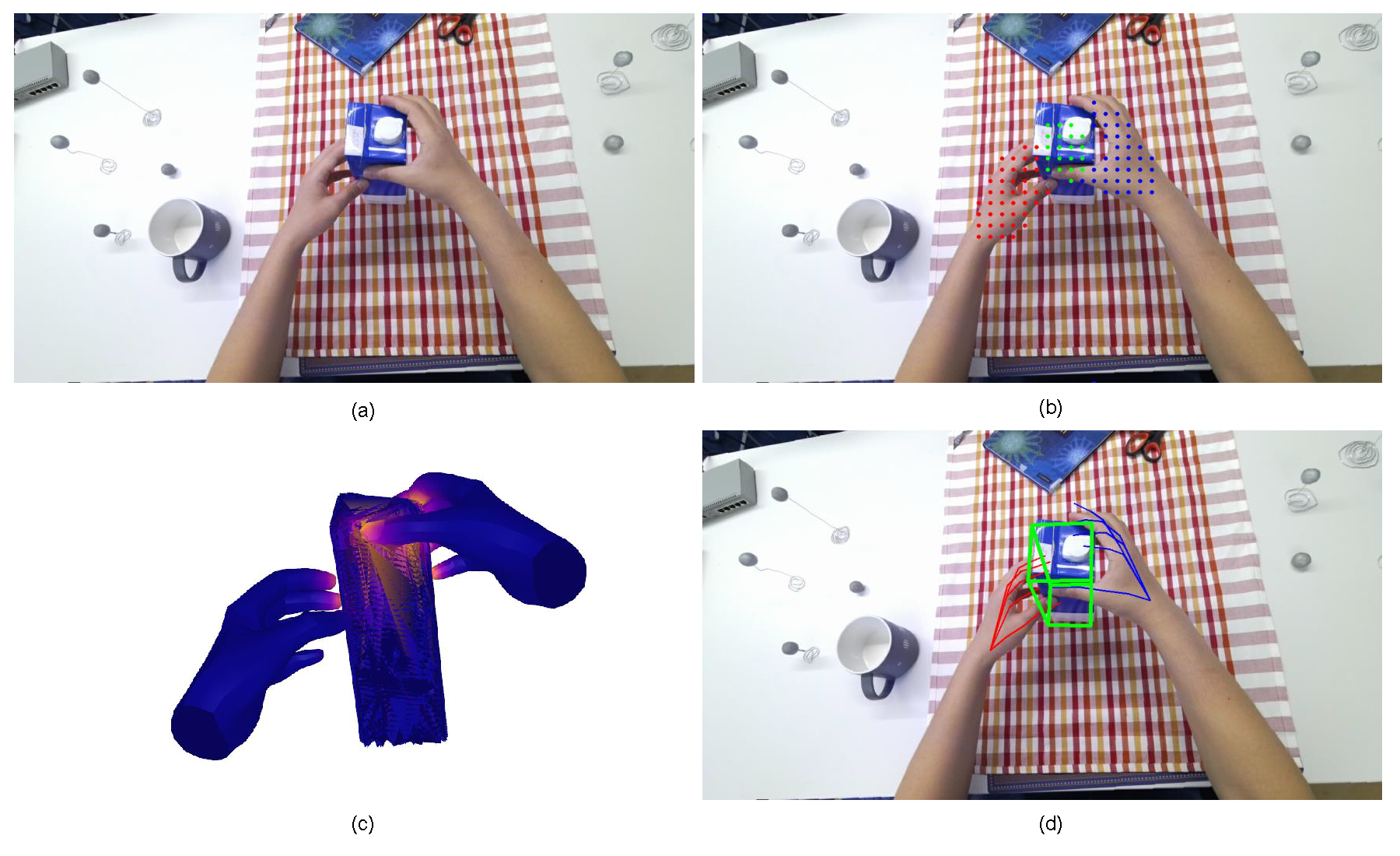
In this paper, we present a query-optimized real-time Transformer (QORT-Former), the first Transformer-based real-time framework for 3D pose estimation of two hands and an object. Our approach optimizes queries to balance efficiency and accuracy, leveraging hand-object contact information and a three-step feature update mechanism. Our method achieves real-time pose estimation at 53.5 FPS on an RTX 3090TI GPU while outperforming state-of-the-art models on H2O and FPHA datasets.